语雀导出文档小工具
# 语雀导出文档小工具
# 功能:
- 模拟用户浏览器操作一篇一篇导出 markdown 文档
- 支持将同名的文档导出
- 支持导出失败重试
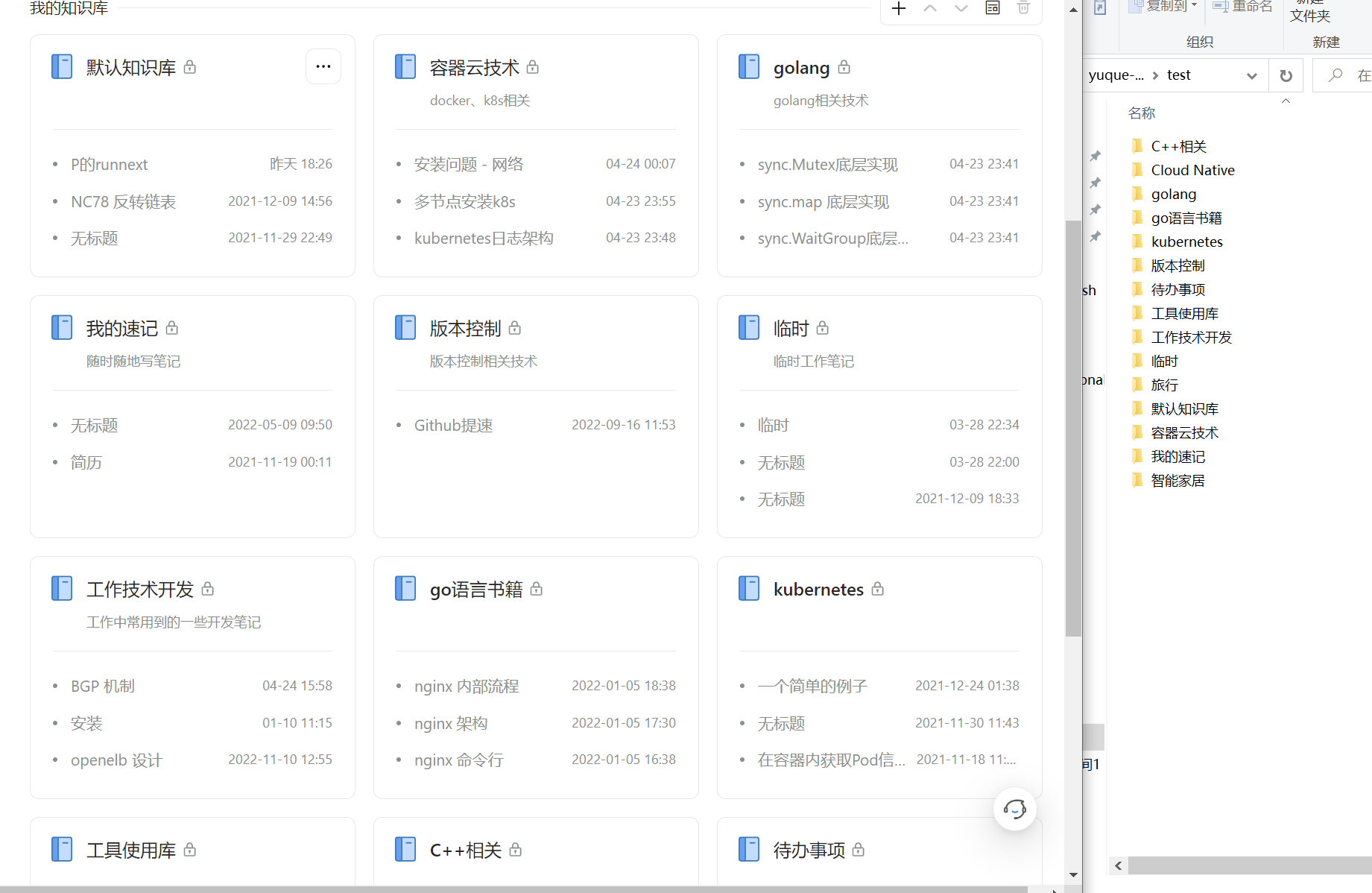
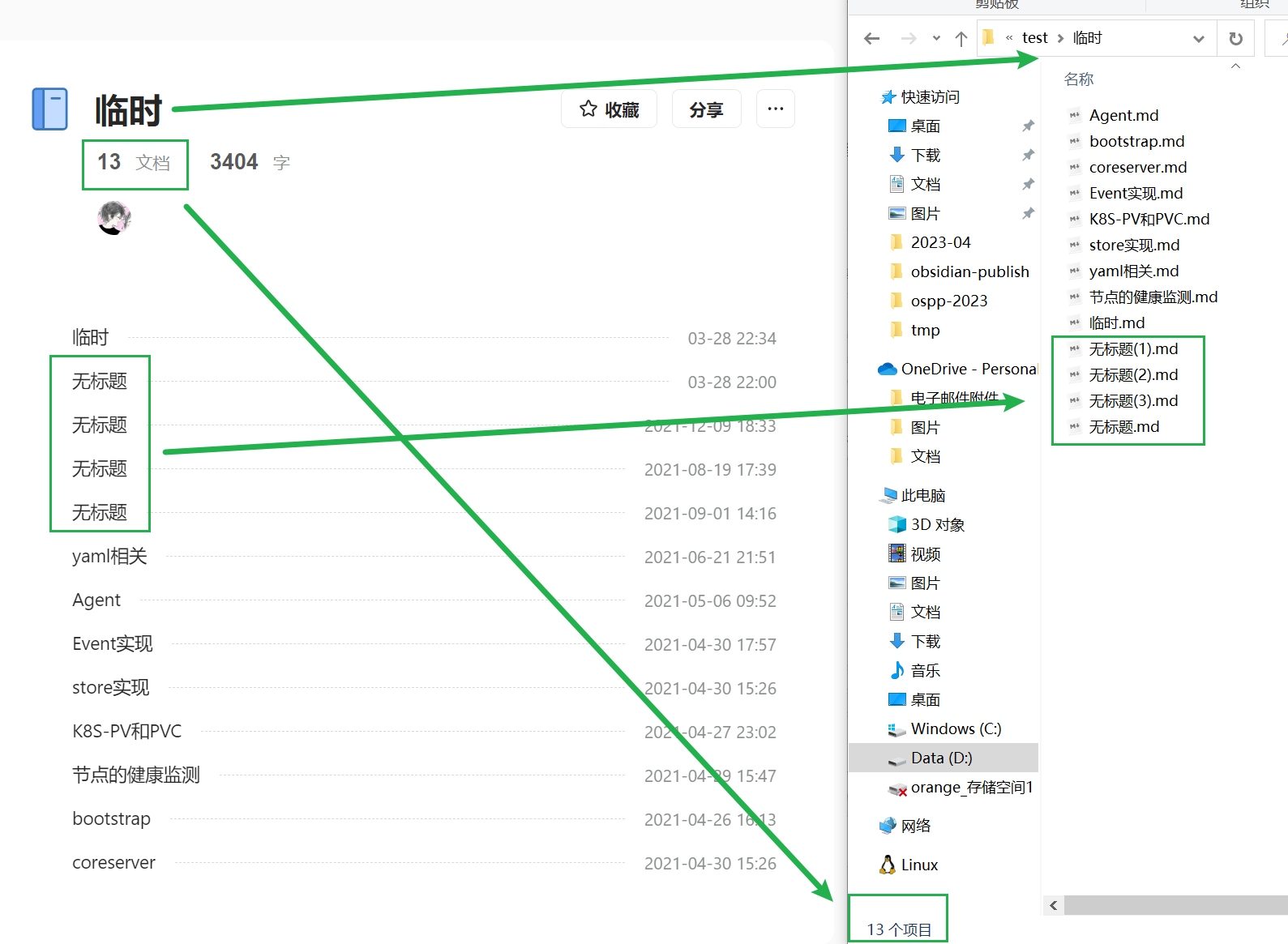
我的知识库与导出文件目录
# 说明:
这是一个基于puppeteer 来模拟用户在浏览器的操作一篇一篇的导出语雀文档的工具。 关于语雀的导出可以详情说明见官方的文档: 如何导入导出知识库
首先语雀支持导出文档为 markdown 格式。 单篇导出:支持导出为 markdown、word、pdf、lakebook等 批量导出:支持导出为 lakebook、pdf 格式。对于超级用户是可以通过创建 token 来使用 官方的 exporter 工具或者其他基于 api 的工具进行批量导出;超级用户的价格为 299/月。
lakebook 格式为语雀私有的格式: lakebook 格式说明,语雀也没有相应的工具去支持迁移/导入到其他笔记软件。pdf 估计也不能直接导入其他笔记软件(这个没有研究过就不展开了)。 因此对于想要迁移自己文档的普通用户以及会员用户来说,你只能一篇一篇导出来完成你的迁移动作,这些用户也大多有上百篇文档,这无疑是劝退。所以我的迁移计划也一再搁置,同时也再等待其他的更友好的导出方式出现。最后还是不想等了,请教 GPT 写了这个工具,确实也怕像我这种白嫖用户之后的迁移的成本越来越大了。
ps: 本人也不是专门写 nodejs 的,代码可能也是烂成狗屎,请大家不喜勿喷。谢谢!
# 使用:
确保你的环境有 Chromium 浏览器
# 1. 获取个人文档访问路径
访问个人账号管理:
https://www.yuque.com/settings/account
个人路径:账号设置 -> 账号管理可以查看已经设置的个人路径 https://www.yuque.com/xxx
# 2. 安装 node 相关的工具
建议使用 nvm 管理 node,选取下列适合自己的方式安装:
- github 地址: nvm-sh/nvm: Node Version Manager
- gitee 地址: nvm-cn: 🧊 nvm国内安装工具 (gitee.com) 配置 npm 淘宝源:npm config set registry https://registry.npm.taobao.org 安装 yarn:npm install -g yarn –registry=https://registry.npm.taobao.org
# 3. 下载代码并运行工具
ubuntu
| |
yarn 安装依赖如果下载报错的话,可以依据情况更换源。
windows
| |
# 存在的问题:
- 无法获取知识库的目录信息,进一步做层级关系的文档导出存储 现在普通用户无法获取知识库中的目录信息,因此知识库文档的导出后全部平铺保存到以知识库名称命名的文件夹中。同名的文档会在文档后面追加数字以区分,知识库目录的分级需要自己根据文档的内容进行调整。
解决办法:访问目录的url为 https://www.yuque.com/r/renyunkang/kb/toc, 有兴趣的可以根据 html 的元素的特征来分析。(我个人没有这个需求也就没有太大关注了,如果你有兴趣或者有需求可以试试,类似自动登录时按照元素匹配数据)
自动登录仅支持账号密码登录
无法保证兼容性,如果之后官方 api 修改后,可以自己根据 api 修改源码
# Q&A
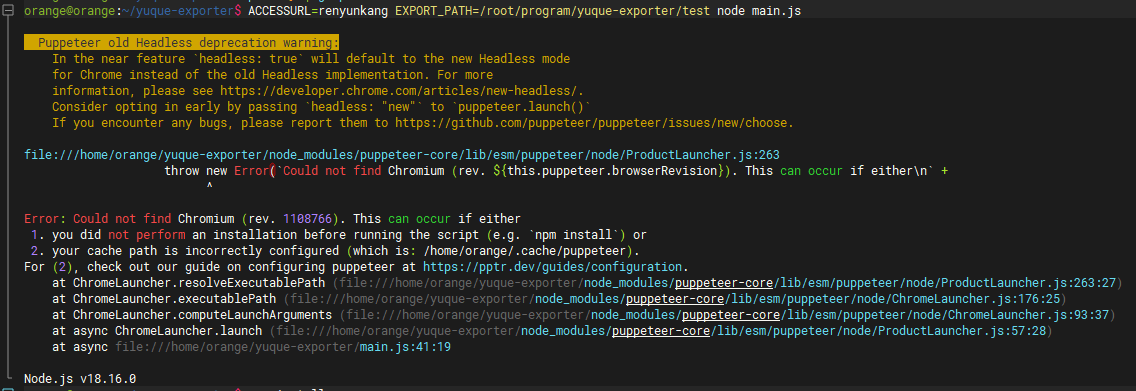
- Could not find Chromium 但是有 chorm 浏览器 在不同的操作系统上,Puppeteer 默认调用的 Chrome 路径如下:
- Windows: C:\Program Files (x86)\Google\Chrome\Application\chrome.exe
- macOS: /Applications/Google Chrome.app/Contents/MacOS/Google Chrome
- Linux: /usr/bin/google-chrome
如果主机上对应的可执行文件路径与默认一致但仍然运行失败,可以修改源码手动指定一下
| |
# 其他
puppeteer 可以更换为其他的同类型产品,自己动手开发:
- selenium
- puppeteer
- chormdp